Universal Data Collector (UDC)
The UDC is one of a core components of L3A Protocol. It facilitates the collection, enhancement, and standardization of a variety of data sources, extracting atomic events and packaging them into indexed data sets that can be used for live-streamed and historical data analytics.
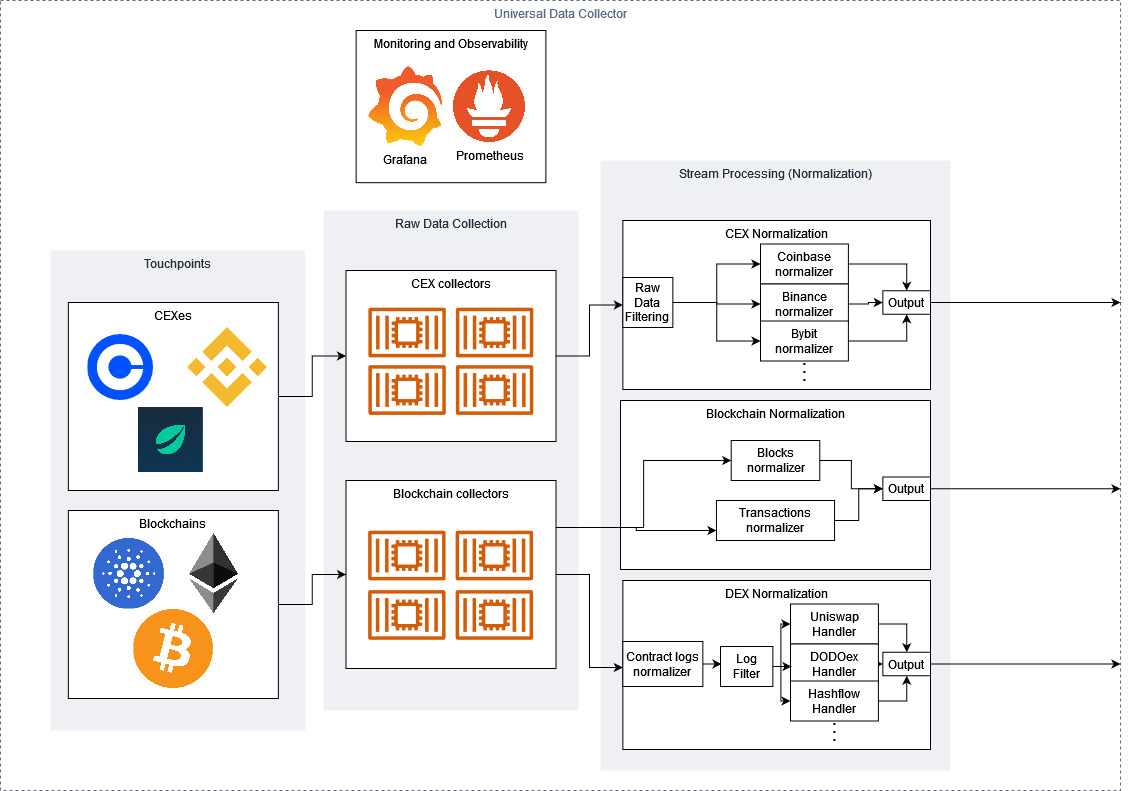
The process begins with the raw data collection, Kubernetes pods which connect to centralized exchange APIs (both HTTP and Websockets) to pull market data directly from the source. These processes are designed to be fault tolerant and to handle any unexpected event from the exchange that could cause an outage or drop in data. Alongside the centralized exchange pods, blockchain data collectors connect directly to blockchain nodes, making JSON RPC calls to pull full, granular data to be processed and transformed into human-readable on-chain events. L3 Atom has been designed to work with any connection to these nodes – it doesn’t rely on existing APIs. If users wish to run a connector themselves, they can run their own nodes or use any provider without worries for incompatibility.
After the raw data is collected, sorted, and enhanced, it’s produced to an Apache Kafka cluster, where a network of stream processors pull the data and process the raw data into standardized events. For CEXes, the raw data is filtered into different categories – first by exchange, then by event type, e.g. an order book update, a new trade, a funding rate update, e.t.c. After the events are filtered, their schemas are transformed to a standardized format, which are then produced back to Kafka to their appropriate topics. Blockchain data is processed in a similar manner, with smart contract events being pre-processed to decipher which DeFi protocol they belong to before being standardized and sorted.
The UDC is monitored via Prometheus, with a public Grafana dashboard that the community can use to gain telemetry into the infrastructure.
Being a community-focussed open source project, the UDC has been designed to make it as easy as possible for community members to expand L3 Atom’s data coverage, with highly modularised and containerised code that can easily extend to any arbitrary data source. The high-level steps to add an additional data source are:
Define the unique connectivity process, e.g. endpoints, subscription methods
Define the normalization procedures
Submit a pull request, and if accepted, the data source will be introduced to L3 Atom as another node on the network
Last updated